Hi @paultaylor,
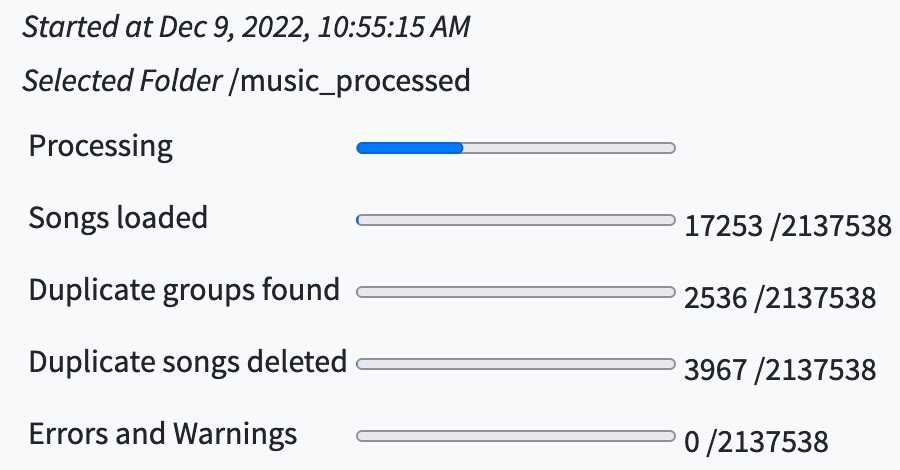
So now that I ended up with one identified music folder, renamed…
I still have the backlog of albums/tracks that songkong did NOT identify.
here is my question, what’s the risk of running another fix tracks job on that one, and simply use tracks tags to rename the files ?
If I do so, will I still be able to run other fix jobs on these already renamed files ? and get them identified the day bandcamp / beatports gets implemented ?
Is there also a risk I could see a “Various_artists - blabla” album renamed and moved in specific artists folders ? like one track per artist, per folder ?