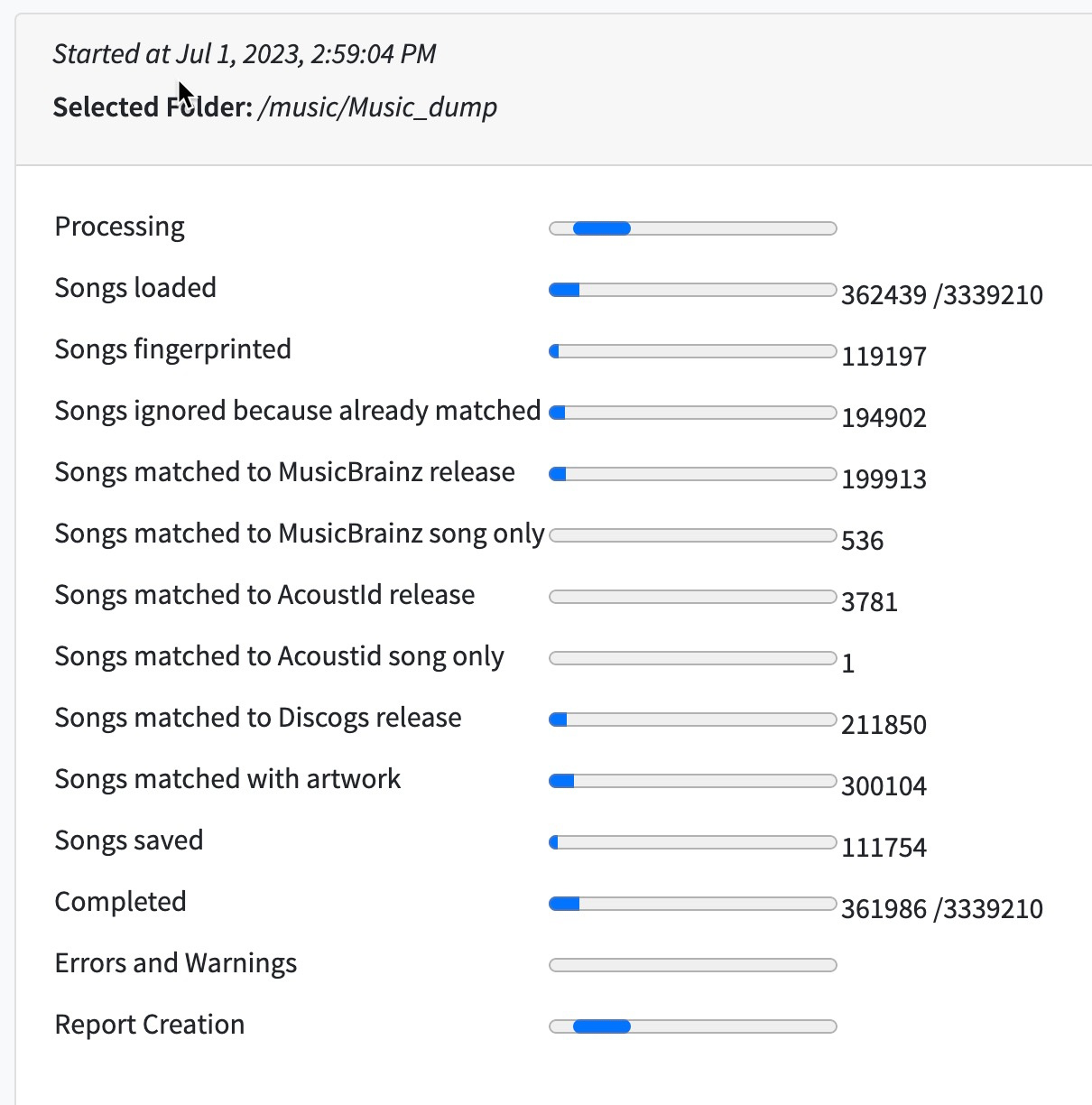
i started a new task. And even with the skip already fixed tracks. It is processing all files again.

So for some reason, songkong takes the 47 tracks processed as truth.
i started a new task. And even with the skip already fixed tracks. It is processing all files again.
So for some reason, songkong takes the 47 tracks processed as truth.
It’s not really processing them it’s sending straight to the completed task without searching for matches or updating tags.
Don’t understand the comment about 47 songs.
it mght be, but then, even with the skip already matched setting, it’s still pretty damn slow :
360k files processed in 28 hours. It’s faster than the original matching time, sure, but it’s still a lot of time just to check the DB if this or that file was already written in it. rght ?
111,754 songs have been saved so indicates that perhaps these files were not part of set matched before, but difficult to say really. Also if you only have skipped already fixed tracks set, it will still retry fixing tracks it has tried before but didn’t fix firs time round.
You need to check Ignore songs prevoously checked that could not be matched to skip songs that failed first time round
Bit stumped on the incorrect summary page, the 1 million song boundary does not seem to be issue, and I cannot find anything else that would cause it. Have to see if it happens again.
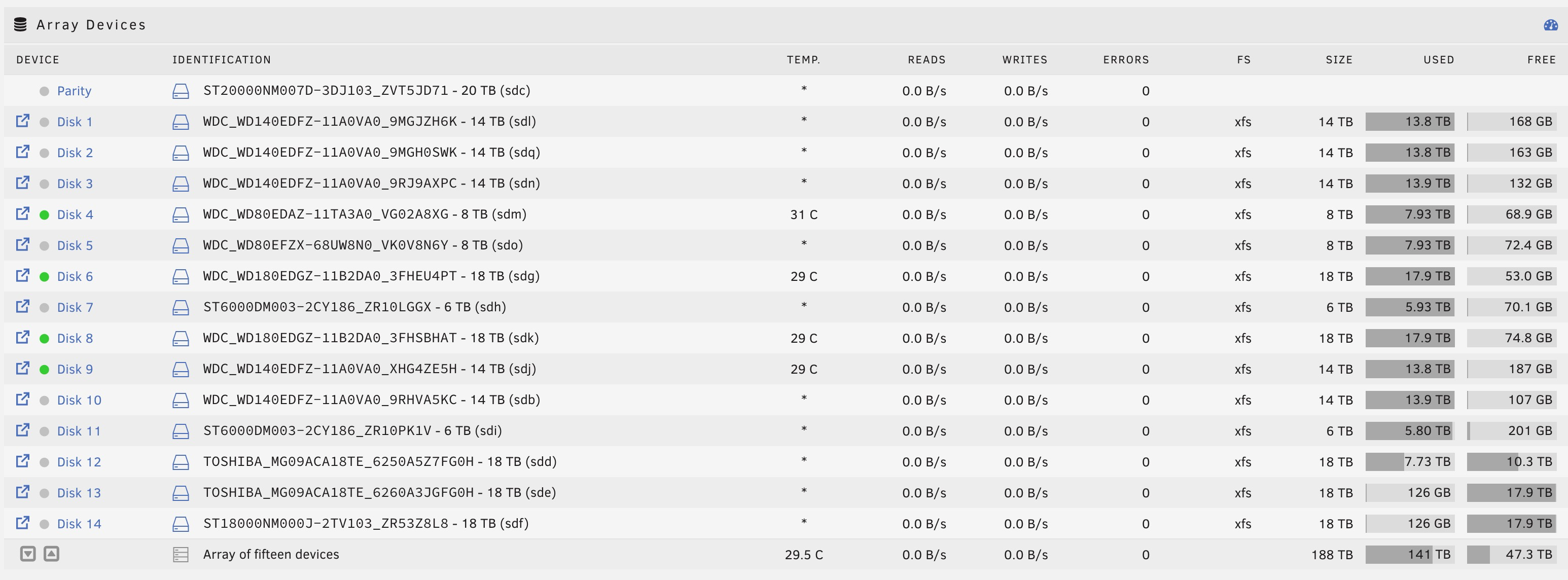
now I remember why I stopped the previous task. It stopped processing my files. I started it again (as you know) and it is blocked again.
as you can see my disks are not running, meaning my array stopped them due to inactivity :
This made me have a look at the status screen of SK, and it is stuk here :
here is what the debug logs shows, repeatingly :
05/07/2023 23.44.07:CEST:MonitorExecutors:run:SEVERE: ----Worker:6
05/07/2023 23.44.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/jdk.internal.misc.Unsafe.park(Native Method)
05/07/2023 23.44.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/java.util.concurrent.locks.LockSupport.park(LockSupport.java:341)
05/07/2023 23.44.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionNode.block(AbstractQueuedSynchronizer.java:505)
05/07/2023 23.44.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/java.util.concurrent.ForkJoinPool.managedBlock(ForkJoinPool.java:3137)
05/07/2023 23.44.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:1614)
05/07/2023 23.44.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/java.util.concurrent.LinkedBlockingQueue.take(LinkedBlockingQueue.java:435)
05/07/2023 23.44.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/java.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1056)
05/07/2023 23.44.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1116)
05/07/2023 23.44.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:630)
05/07/2023 23.44.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/java.lang.Thread.run(Thread.java:832)
05/07/2023 23.44.07:CEST:MonitorExecutors:run:SEVERE: ----Worker:11
05/07/2023 23.44.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/jdk.internal.misc.Unsafe.park(Native Method)
05/07/2023 23.44.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/java.util.concurrent.locks.LockSupport.park(LockSupport.java:341)
05/07/2023 23.44.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionNode.block(AbstractQueuedSynchronizer.java:505)
05/07/2023 23.44.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/java.util.concurrent.ForkJoinPool.managedBlock(ForkJoinPool.java:3137)
05/07/2023 23.44.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:1614)
05/07/2023 23.44.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/java.util.concurrent.LinkedBlockingQueue.take(LinkedBlockingQueue.java:435)
05/07/2023 23.44.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/java.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1056)
05/07/2023 23.44.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1116)
05/07/2023 23.44.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:630)
05/07/2023 23.44.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/java.lang.Thread.run(Thread.java:832)
05/07/2023 23.44.07:CEST:MonitorExecutors:run:SEVERE: ----Worker:32
05/07/2023 23.44.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/jdk.internal.misc.Unsafe.park(Native Method)
05/07/2023 23.44.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/java.util.concurrent.locks.LockSupport.park(LockSupport.java:341)
05/07/2023 23.44.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionNode.block(AbstractQueuedSynchronizer.java:505)
05/07/2023 23.44.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/java.util.concurrent.ForkJoinPool.managedBlock(ForkJoinPool.java:3137)
05/07/2023 23.44.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:1614)
05/07/2023 23.44.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/java.util.concurrent.LinkedBlockingQueue.take(LinkedBlockingQueue.java:435)
05/07/2023 23.44.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/java.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1056)
05/07/2023 23.44.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1116)
05/07/2023 23.44.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:630)
05/07/2023 23.44.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/java.lang.Thread.run(Thread.java:832)
05/07/2023 23.44.07:CEST:MonitorExecutors:run:SEVERE: ----Worker:36
05/07/2023 23.44.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/jdk.internal.misc.Unsafe.park(Native Method)
05/07/2023 23.44.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/java.util.concurrent.locks.LockSupport.park(LockSupport.java:341)
05/07/2023 23.44.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionNode.block(AbstractQueuedSynchronizer.java:505)
05/07/2023 23.44.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/java.util.concurrent.ForkJoinPool.managedBlock(ForkJoinPool.java:3137)
05/07/2023 23.44.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:1614)
05/07/2023 23.44.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/java.util.concurrent.LinkedBlockingQueue.take(LinkedBlockingQueue.java:435)
05/07/2023 23.44.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/java.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1056)
05/07/2023 23.44.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1116)
05/07/2023 23.44.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:630)
05/07/2023 23.44.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/java.lang.Thread.run(Thread.java:832)
05/07/2023 23.49.07:CEST:MonitorExecutors:outputQueueSize:SEVERE: QueueSize:Worker:0:32
05/07/2023 23.49.07:CEST:MonitorExecutors:outputQueueSize:SEVERE: QueueSize:SongSaver:0:2
05/07/2023 23.49.07:CEST:MonitorExecutors:outputPipelines:SEVERE: DbConnectionsOpen:3
05/07/2023 23.49.07:CEST:MonitorExecutors:outputPipelines:SEVERE: SongPreMatcherMatcher:0:0:0:0
05/07/2023 23.49.07:CEST:MonitorExecutors:outputPipelines:SEVERE: NaimMatcher:0:0:0:0
05/07/2023 23.49.07:CEST:MonitorExecutors:outputPipelines:SEVERE: AcoustidSubmitter:53199
05/07/2023 23.49.07:CEST:MonitorExecutors:outputPipelines:SEVERE: StartMatcher:75320:75320:53835:719713
05/07/2023 23.49.07:CEST:MonitorExecutors:outputPipelines:SEVERE: MusicBrainzSongGroupMatcher1:26053:26053:26053:229154
05/07/2023 23.49.07:CEST:MonitorExecutors:outputPipelines:SEVERE: MusicBrainzUpdateSongOnly:0:0:0:0
05/07/2023 23.49.07:CEST:MonitorExecutors:outputPipelines:SEVERE: MusicBrainzMetadataMatches:0:0:0:0
05/07/2023 23.49.07:CEST:MonitorExecutors:outputPipelines:SEVERE: MusicBrainzSongGroupMatcher2(SubGroupAnalyser):0:0:0:0
05/07/2023 23.49.07:CEST:MonitorExecutors:outputPipelines:SEVERE: MusicBrainzSongGroupMatcher3(WithoutDuplicates):61:61:61:1789
05/07/2023 23.49.07:CEST:MonitorExecutors:outputPipelines:SEVERE: MusicBrainzSongGroupMatcher4(AnalyserArtistFolder):0:0:0:0
05/07/2023 23.49.07:CEST:MonitorExecutors:outputPipelines:SEVERE: DiscogsMultiFolderSongGroupMatcher:5693:5693:5693:61189
05/07/2023 23.49.07:CEST:MonitorExecutors:outputPipelines:SEVERE: DiscogsSongGroupMatcher:5693:5693:5693:61189
05/07/2023 23.49.07:CEST:MonitorExecutors:outputPipelines:SEVERE: MusicBrainzSongMatcher:0:0:0:0
05/07/2023 23.49.07:CEST:MonitorExecutors:outputPipelines:SEVERE: DiscogsSongMatcher:225:225:225:225
05/07/2023 23.49.07:CEST:MonitorExecutors:outputPipelines:SEVERE: DiscogsUpdateSongGroup:13322:13322:13322:103179
05/07/2023 23.49.07:CEST:MonitorExecutors:outputPipelines:SEVERE: SongSaver:75534:75534:75534:719713
05/07/2023 23.49.07:CEST:MonitorExecutors:run:SEVERE: MusicBrainzQueries:109464
05/07/2023 23.49.07:CEST:MonitorExecutors:run:SEVERE: DiscogsQueries:37636
05/07/2023 23.49.07:CEST:MonitorExecutors:run:SEVERE: ----Worker:8
05/07/2023 23.49.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/jdk.internal.misc.Unsafe.park(Native Method)
05/07/2023 23.49.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/java.util.concurrent.locks.LockSupport.park(LockSupport.java:341)
05/07/2023 23.49.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionNode.block(AbstractQueuedSynchronizer.java:505)
05/07/2023 23.49.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/java.util.concurrent.ForkJoinPool.managedBlock(ForkJoinPool.java:3137)
05/07/2023 23.49.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:1614)
05/07/2023 23.49.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/java.util.concurrent.LinkedBlockingQueue.take(LinkedBlockingQueue.java:435)
05/07/2023 23.49.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/java.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1056)
05/07/2023 23.49.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1116)
05/07/2023 23.49.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:630)
05/07/2023 23.49.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/java.lang.Thread.run(Thread.java:832)
05/07/2023 23.49.07:CEST:MonitorExecutors:run:SEVERE: ----Worker:14
05/07/2023 23.49.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/jdk.internal.misc.Unsafe.park(Native Method)
05/07/2023 23.49.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/java.util.concurrent.locks.LockSupport.park(LockSupport.java:341)
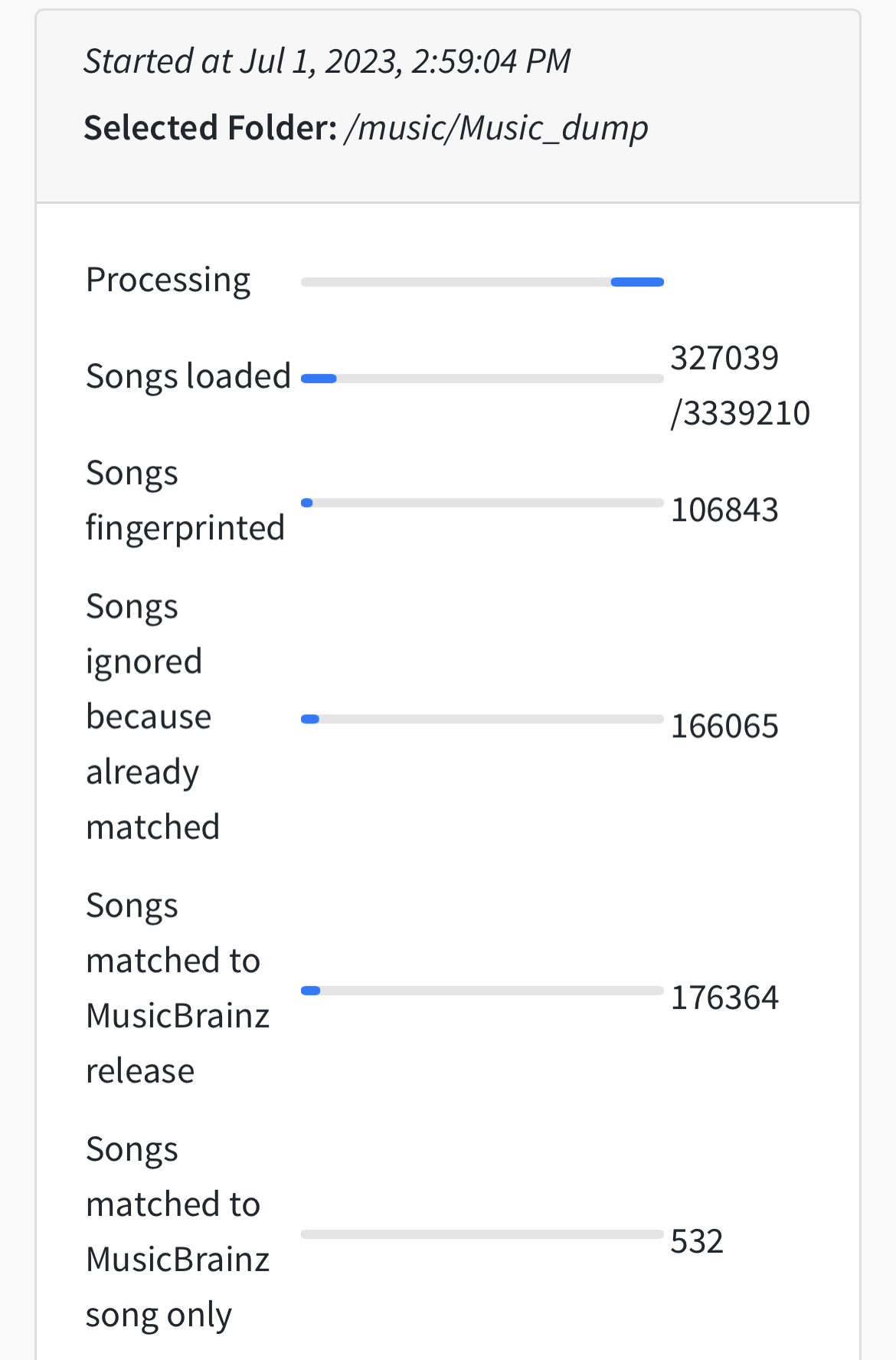
I see no reason why this would have crashed on my end so I suspect something bad happened on server side again. Thing is, I already spent almost 20 days trying to get this to work. Each time I restart the process, I’m loosing several days again waiting for SK to check the already processed files again.
So should I stop it again now ? and start again ? 
Hi, okay I have checked server and it is fine with no errors reported.
Looking at the log extract all the pipelines including MusicBrainzMatcher1 and SongSaver have completed all the tasks sent to their queues except StartMatcher, this has only completed 53,835 of 75,320 tasks it is not clear why this is.
There are a number of worker threads to do work on the queue when their stacktrrace says
java.base@14.0.2/jdk.internal.misc.Unsafe.park(Native Method)
05/07/2023 23.49.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/java.util.concurrent.locks.LockSupport.park(LockSupport.java:341)
05/07/2023 23.49.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionNode.block(AbstractQueuedSynchronizer.java:505)
05/07/2023 23.49.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/java.util.concurrent.ForkJoinPool.managedBlock(ForkJoinPool.java:3137)
05/07/2023 23.49.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:1614)
05/07/2023 23.49.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/java.util.concurrent.LinkedBlockingQueue.take(LinkedBlockingQueue.java:435)
05/07/2023 23.49.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/java.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1056)
05/07/2023 23.49.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1116)
05/07/2023 23.49.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:630)
05/07/2023 23.49.07:CEST:MonitorExecutors:run:SEVERE: java.base@14.0.2/java.lang.Thread.run(Thread.java:832)
This means they are just waiting to do something, they have no tasks to do.
So the question is are all the threads just waiting to do something, or are some busy ?
What is the last actual work done by the tasks, have tasks been timing out and the timeout is not wotrking properly ?
If you could leave running for now, but zip up the logs folder and send it to support@jthink.net that would be helpful.
If at some time point you do restart then two points to consider:
If database is fine, then SongKong reads every file already added to database direct from database to check, But if database corrupted for some reason then it will have to read song from music file itself which is significantly slower.
You need to have checked Ignore songs previously checked that could not be matched to prevent rematching of songs that failed to match first time, as well as setting For songs already matched to Ignore to skip over songs already matched.
Hi again,
now regarding the process itself :
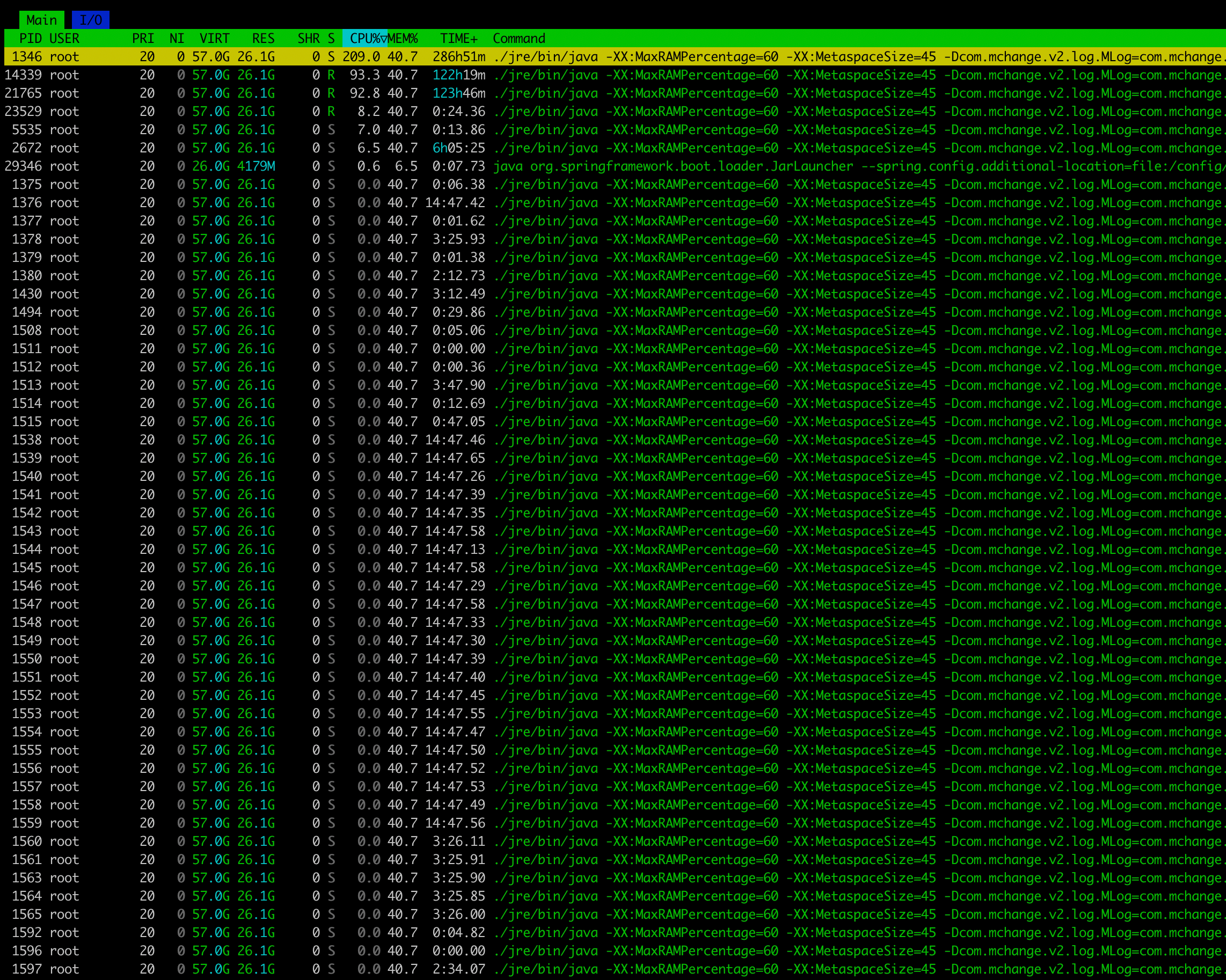
some cores are used, indeed, and I can see SK do process. afew files here and there.
I am zipping the logs and will send them in a few minutes. 
Not really, there may be errors in logs that indicate issue but since your Errors and Warnings progress bar is at zero seems unlikely. I think would only be issue for next job if you stopped this job and this exposed some database issue that caused it to need to be recreated for next run.
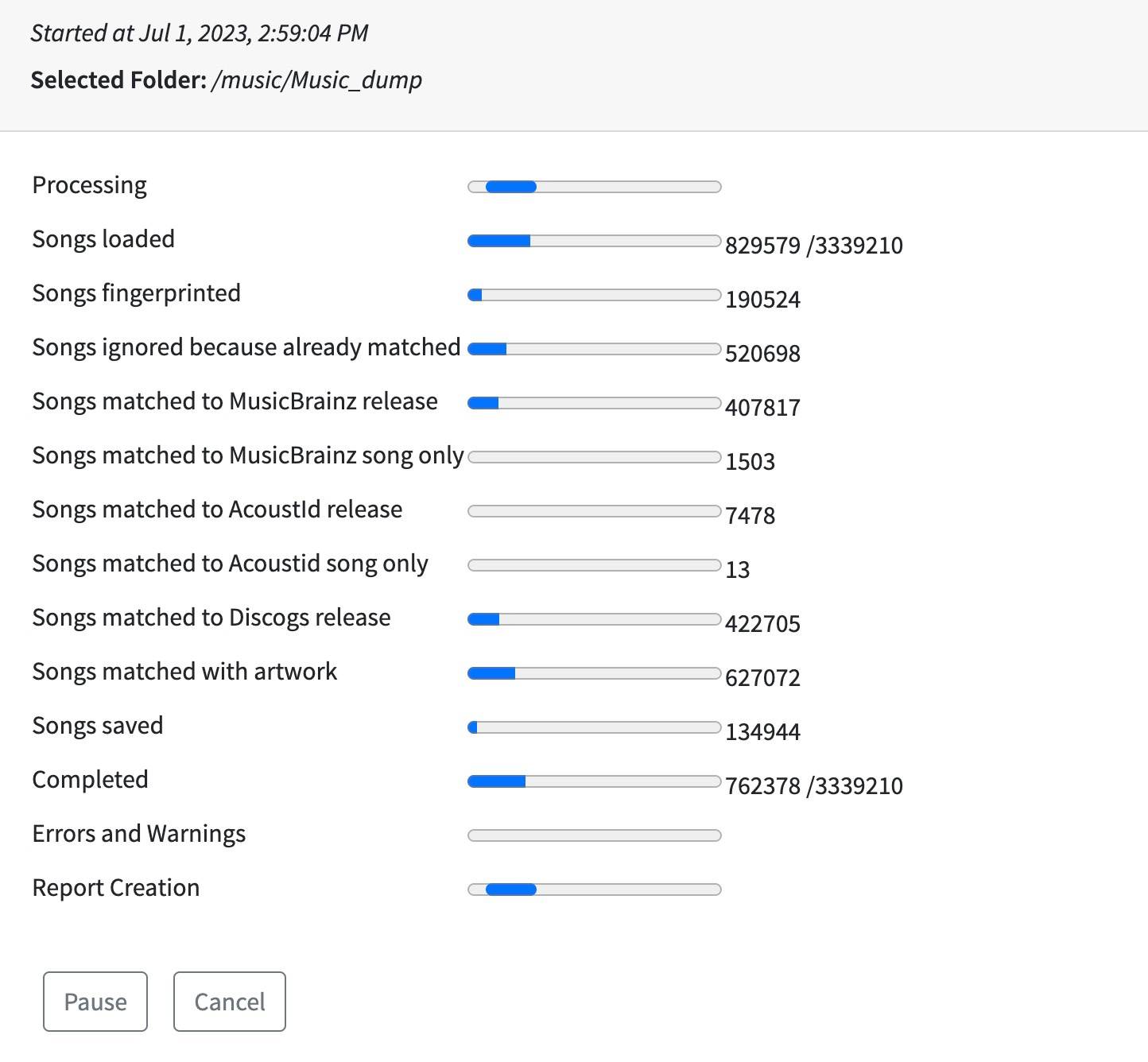
HI, thanks okay it is still working (SongSaver gone up from (71,9713 files to 81,9231 files) , but slowly…
07/07/2023 11.39.07:CEST:MonitorExecutors:outputQueueSize:SEVERE: QueueSize:Worker:0:32
07/07/2023 11.39.07:CEST:MonitorExecutors:outputQueueSize:SEVERE: QueueSize:SongSaver:0:2
07/07/2023 11.39.07:CEST:MonitorExecutors:outputPipelines:SEVERE: DbConnectionsOpen:3
07/07/2023 11.39.07:CEST:MonitorExecutors:outputPipelines:SEVERE: SongPreMatcherMatcher:0:0:0:0
07/07/2023 11.39.07:CEST:MonitorExecutors:outputPipelines:SEVERE: NaimMatcher:0:0:0:0
07/07/2023 11.39.07:CEST:MonitorExecutors:outputPipelines:SEVERE: AcoustidSubmitter:54648
07/07/2023 11.39.07:CEST:MonitorExecutors:outputPipelines:SEVERE: StartMatcher:86065:86065:61059:819231
07/07/2023 11.39.07:CEST:MonitorExecutors:outputPipelines:SEVERE: MusicBrainzSongGroupMatcher1:28820:28820:28820:251825
07/07/2023 11.39.07:CEST:MonitorExecutors:outputPipelines:SEVERE: MusicBrainzUpdateSongOnly:0:0:0:0
07/07/2023 11.39.07:CEST:MonitorExecutors:outputPipelines:SEVERE: MusicBrainzMetadataMatches:0:0:0:0
07/07/2023 11.39.07:CEST:MonitorExecutors:outputPipelines:SEVERE: MusicBrainzSongGroupMatcher2(SubGroupAnalyser):0:0:0:0
07/07/2023 11.39.07:CEST:MonitorExecutors:outputPipelines:SEVERE: MusicBrainzSongGroupMatcher3(WithoutDuplicates):84:84:84:2003
07/07/2023 11.39.07:CEST:MonitorExecutors:outputPipelines:SEVERE: MusicBrainzSongGroupMatcher4(AnalyserArtistFolder):0:0:0:0
07/07/2023 11.39.07:CEST:MonitorExecutors:outputPipelines:SEVERE: DiscogsMultiFolderSongGroupMatcher:6241:6241:6241:66788
07/07/2023 11.39.07:CEST:MonitorExecutors:outputPipelines:SEVERE: DiscogsSongGroupMatcher:6241:6241:6241:66788
07/07/2023 11.39.07:CEST:MonitorExecutors:outputPipelines:SEVERE: MusicBrainzSongMatcher:0:0:0:0
07/07/2023 11.39.07:CEST:MonitorExecutors:outputPipelines:SEVERE: DiscogsSongMatcher:242:242:242:242
07/07/2023 11.39.07:CEST:MonitorExecutors:outputPipelines:SEVERE: DiscogsUpdateSongGroup:15322:15322:15322:118387
07/07/2023 11.39.07:CEST:MonitorExecutors:outputPipelines:SEVERE: SongSaver:86313:86313:86313:819231
Im sorry I have a three hour drive soon, so I will have to come back to this later. Im thinking about this but I dont have answer or reason for you at moment.
Looking at it again, the total number of files to be processed by StartMatcher matches the total number of files to be processed by SongSaver. So I think StartMatcher tasks have actually completed and moved to next task and eventually got to SongSaver (All files go to SongSaver task even if no actual save needed so it actually correlates to Completed progress bar). i.e there is a simple bug in the logging that is not reporting all exits correctly from StartMatcher
And the queues are empty, and workers idle
So it seems that maybe the limiting factor is the songloader, for some reason not loading files quick enough to give the workers much work. But I cannot see why this would be, and why it would be slower than when you originally started, but I will review the code.
I originally thought that all was working and then something actually broke. But now I’m thinking that the issue is songloader reading from files is too slow since song loader is single threaded. But because you had restarted task the first 500,000 songs were already in database from last time. So although it had to traverse filesystem it didn’t have to read the actual files themselves (just read from database) so loaded quick enough, but now when get to new files slowed significantly.
I have never noticed this problem. But you previously noted issue with reading raid disks so is it a file i/o issue specific to raid?
Or maybe since you have alot of cpus , the mismatch between 1 fir loading and 32 for processing is too much.So I dont think restarting is going to help at all.
The only thing that might be interesting is to run Status Report over everything. This is a relatively simple task that just reads each file, counts some stats and create report with summary stats and song details. But it does need to load each file into database, so it would be interesting to see if it performs badly for you. Also if it completes all file info should then be in database for subsequent Fix Songs task possibly allowing to run at good throughput.
This may sound as a stupid question, but is there no way to allow more cores to the songloader ?
Not currently, because in all my testing the songloader is waiting for the workers and song savers, there is no need for songloader to work quicker because there is sufficient work in the queue.
But I’m going to look at it this week
Are you still running the task?
yes, but as far as I am looking at my array usage, I can say disks are sometimes not accessed for very long periods.
your theory seems to be right, If I look closely to the disk activity, I see one of my disk will get read, and writes will then happen. It will works like this for some time, the time to process all the files that were shot to the workers.
But in between the “working” workers, and the next batch of files that will be processed, I have a lonf time where nothing actually happens. I don’t believe this is due to my array. Sure, there is some write speed nonsense under unraid, but I do not believe this is the reason why this task is running that slow. anyway, I’m abroad for a couple of weeks, I’ll keep it running, and will check from time to time what the advancement it 
Improvements made to Fix Songs Song Loader made so multithreaded, and to the MonitorExecutors logging made in SongKong 9.3 Aerial released 12th of July 2023
Great! I was sitting at 1.141.448 files. I will start a new fix task once updated.
Hi, that would be interesting if you did, and sent supprt files.
Looked at FixSongsReport0102 nothing much to report except I see you have encountered another obscure error, seems to be a limit of 1048576 rows being added to one sheet of an Excel spreadsheet, not sure if this is still a limit of later versions of Excel or just the lib I am using to create Excel format spreadsheets - https://jthink.atlassian.net/jira/software/c/projects/SONGKONG/issues/SONGKONG-2465