Hi @paultaylor!
Debugging is quite hard as I am 2000lm away from home but since I remotely updated sonkong to version 9.3, I’ve got my whole docker service crashed due to the fact the vdisk completely filed !
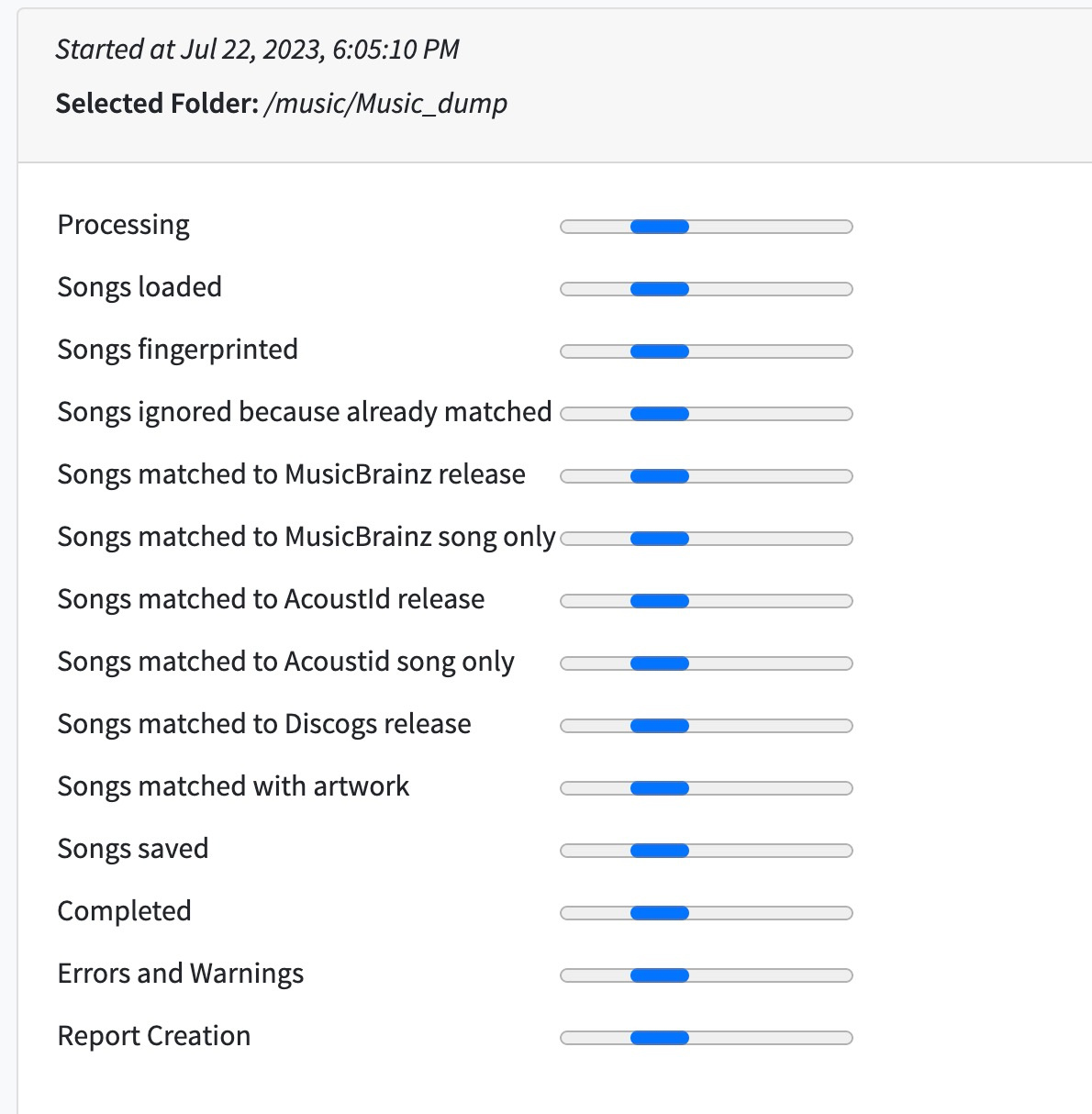
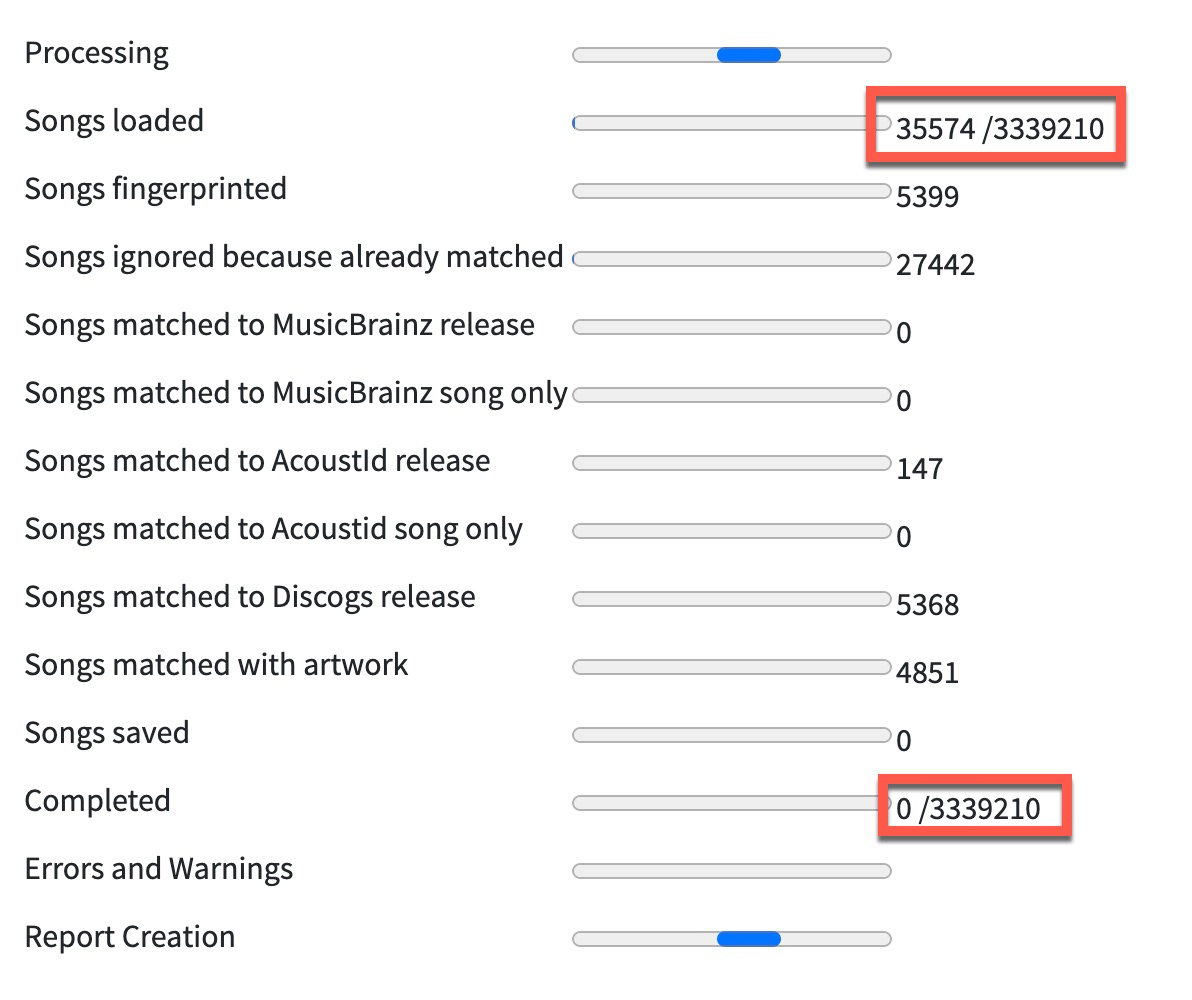
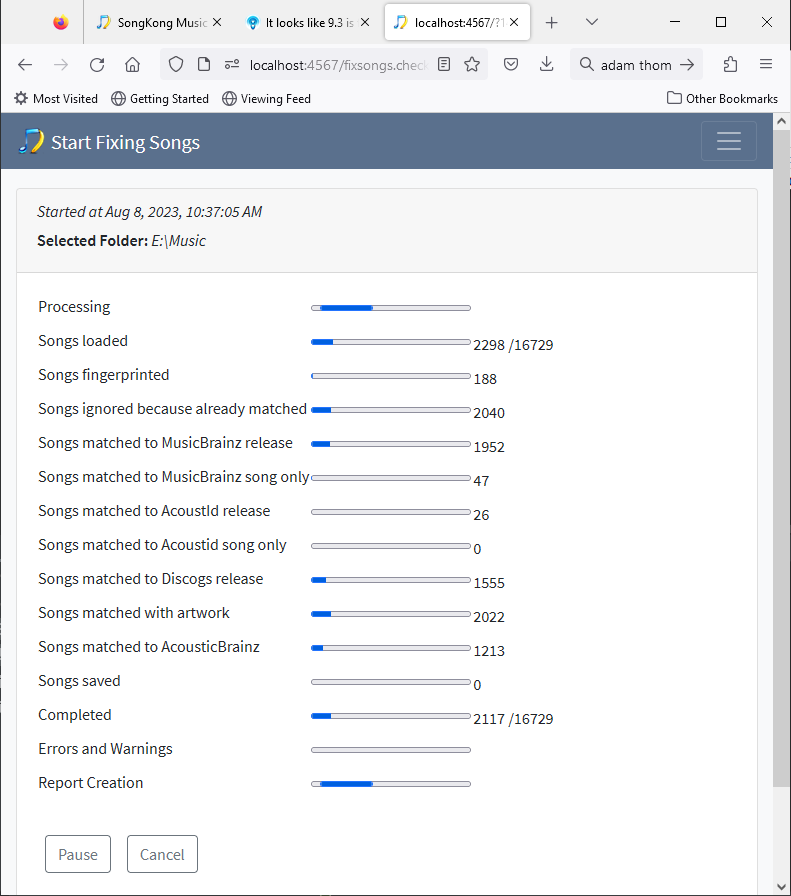
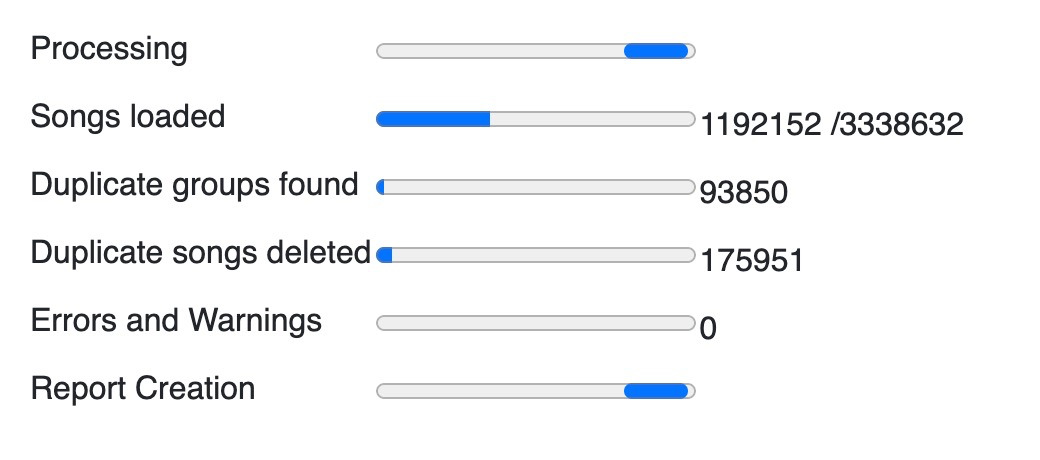
This happened right after I stared a simple file indexation task (not sure about the right name for it anymore, sorry).
The vdisk did quickly grow to 100% usage, which not only killed my sk docker, but also all my other docker containers.
I had to ask my brother to drive to my home, stop the docker deamon, raise the docker img file size from 50 to 100gb, and restart the server in order to get things back online.
I then started the task again, around 5pm, and it filled the extra 50gb after a few hours.
Unfortunately I can’t ask my brother to drive to my place again, and he is ain’t that tech savvy anyway so I cannot ask hip to start reading and understanding the logs. But basically, sk is not reachable anymore. I also can’t reach out to my unraid server using its webui, as my nginx docker container is broken due to this full vdisk image.
I just want to flag there is something wrong with 9.3 that fills the vdisk img file. Could you eventually test this under unraid? Update to 9.3, run a task (the simple indexing one), and watch the img file size.
Thanks!