Hi Paul,
Thanks in advance for your help.
I kicked off Jaikoz Auto Correct on a larger collection of around 8000 tracks last night to test Jaikoz on a more realistic subset of my collection before I commit to making the license purchase. I should mention that I am running on a 4 core (8 threads) 64 bit Linux machine.
The next morning I could see that Album Art exists for under 15% of the tracks. I believe that many of those tracks already had Album Art, so actually the percentage successfully added by Jaikoz is probably much lower than that. Assuming that some of the automatic changes were probably to the wrong album and will probably need manual adjustment I’m thinking that the success rate will be even lower still. It would be useful if Jaikoz could output some statistics after each operation regarding how many tags of which type where changed, added, or deleted.
Can anyone help? Unless there is a way of increasing the success rate I don’t think Jaikoz is going to be a feasible way of adding the correct Album Art to my library.
All of the tracks have existing tag data for at least Title, Artist, Album and Track Number. In some cases they even have Year. The tracks have all been ripped from CDs using Windows Media Player and are all organized neatly in directories according to Artist/Album/Tracks.wma.
All I want to do for now is to add Album art where it is missing (and ensure that the tracks that live in the same directory get assigned the same correct album art). I don’t care so much about MusicBrainz Id’s at this point since I believe that my meta data is in reasonable shape for these directories and I don’t want the MusicBrainz metadata to overwrite my metadata unless I’m absolutely sure that it’s improving data quality.
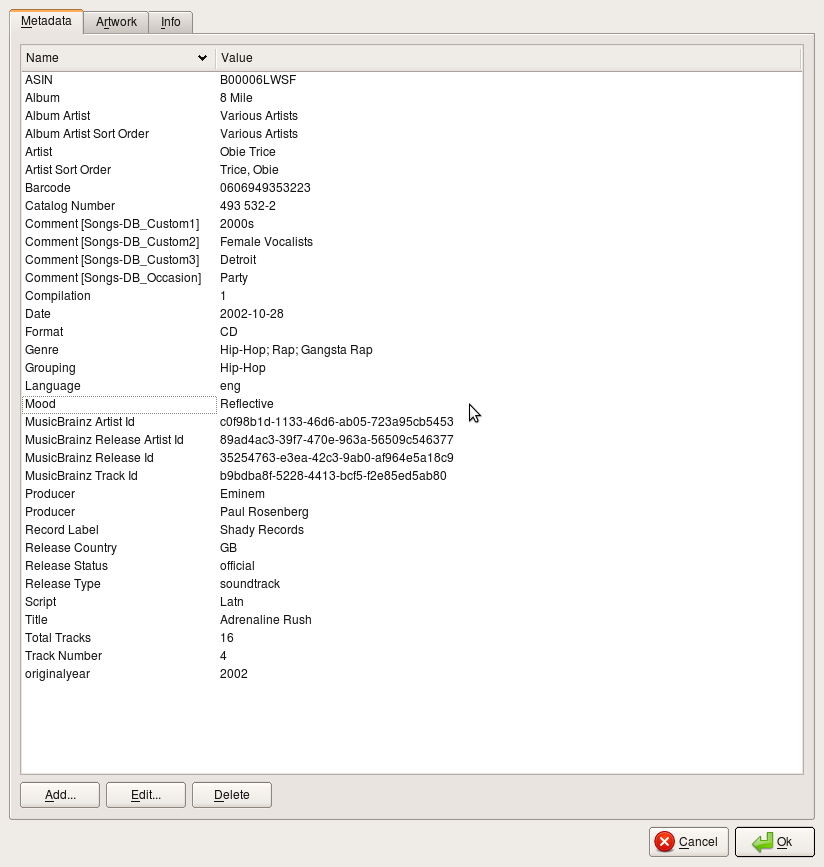
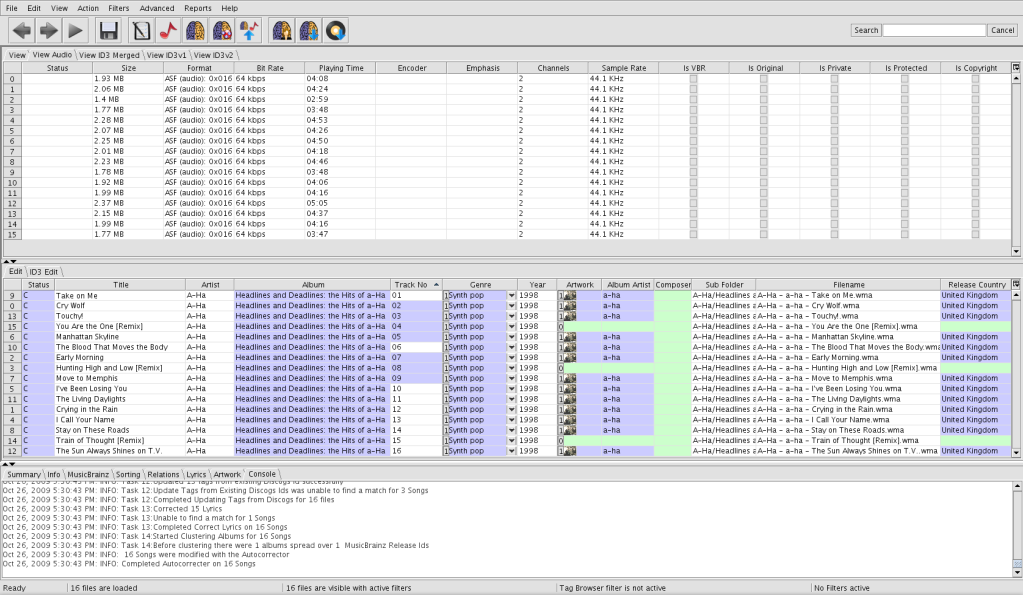
In case it helps. here is a concrete example which illustrates some of the problems. I have taken one Album in a single directory called Eminem - 8 Mile. As you can see from the attached screenshot Jaikoz assigns artwork to only 4 out of 16 tracks but Lyrics to 8 out of 16. No Accoustic Id can be generated for any of the songs. I believe this is because Jaikoz fails for generate Accoustic Id for all WMA files. Is this a bug? Jaikoz claims to support WMA:
http://www.jthink.net/jaikoz/jsp/overview/startup.jsp
Regardless, I would expect that Jaikoz should be able to find album art without MB Id’s given a reasonable amount of meta data. [Aside - Logically I’m reasoning that if this were not the case then Jaikoz would be completely reliant on successful Acoustic Id generation to be able to function at all, and this would mean that Jaikoz would therefore be completely dependent on the quality and coverage of data in the MusicBrainz database rather than the meta data already in the libraries of users. This would also mean that Jaikoz would be unable to take reasonable meta-data that users already have in their ripped collections and contribute to MB by adding the albums into MB.]
The correct MB release page for this album is here:
http://musicbrainz.org/show/release/?mbid=35254763-e3ea-42c3-9ab0-af964e5a18c9
As you can see from my screenshot Jaikoz has a wealth of information that it could potentially use for matching:
- Title matches exactly for every track (even case matches)
- Album matches exactly
- Track number matches exactly
- Playing time matches to within a second or two for every track
- Year matches
- Other tracks with the same Album name and in the same directory are able to be successfully matched to the same correct MB release
- Total number of tracks in directory matches total number of tracks in release. All track numbers are unique within the directory and the highest track number matches with the number of tracks in the correct release
I realize that fuzzy matching algorithms can be tricky, but one would think that all of the above would be sufficient for Jaikoz to have a high degree of certainty regarding which release to choose, but in 12 out of 16 cases it seems unable to select a release automatically.
The only deficiency in the prior existing meta data in this example is that the Artist does not match and Album Artist is empty. In all cases, my tracks have the artist as “Eminem” whereas in MB the tracks are attributed to different artists. In MB Album Artist is “Various Artists”.
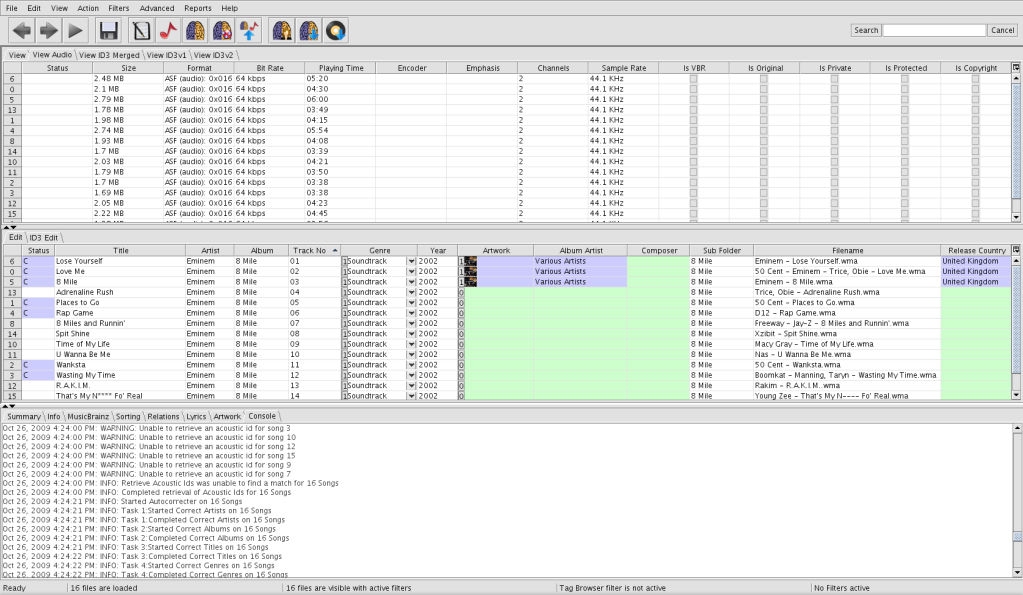
Here’s the console output:
Oct 26, 2009 4:24:21 PM: INFO: Started Autocorrecter on 16 Songs
Oct 26, 2009 4:24:21 PM: INFO: Task 1:Started Correct Artists on 16 Songs
Oct 26, 2009 4:24:21 PM: INFO: Task 1:Completed Correct Artists on 16 Songs
Oct 26, 2009 4:24:21 PM: INFO: Task 2:Started Correct Albums on 16 Songs
Oct 26, 2009 4:24:21 PM: INFO: Task 2:Completed Correct Albums on 16 Songs
Oct 26, 2009 4:24:21 PM: INFO: Task 3:Started Correct Titles on 16 Songs
Oct 26, 2009 4:24:22 PM: INFO: Task 3:Completed Correct Titles on 16 Songs
Oct 26, 2009 4:24:22 PM: INFO: Task 4:Started Correct Genres on 16 Songs
Oct 26, 2009 4:24:22 PM: INFO: Task 4:Completed Correct Genres on 16 Songs
Oct 26, 2009 4:24:22 PM: INFO: Task 5:Started Correct Comments on 16 Songs
Oct 26, 2009 4:24:22 PM: INFO: Task 5:Completed Correct Comments on 16 Songs
Oct 26, 2009 4:24:22 PM: INFO: Task 6:Started Correct Track Numbers on 16 Songs
Oct 26, 2009 4:24:22 PM: INFO: Task 6:Completed Correct Track Numbers on 16 Songs
Oct 26, 2009 4:24:22 PM: INFO: Task 7:Started Correct Recording Times on 16 Songs
Oct 26, 2009 4:24:22 PM: INFO: Task 7:Completed Correct Recording Times on 16 Songs
Oct 26, 2009 4:24:22 PM: INFO: Task 8:Started Correct Tags from Filename on 16 Songs
Oct 26, 2009 4:24:22 PM: INFO: Task 8:Completed Correct Tags from Filename on 16 Songs
Oct 26, 2009 4:24:22 PM: INFO: Task 9:Started Correct Artists on 16 Songs
Oct 26, 2009 4:24:22 PM: INFO: Task 9:Completed Correct Artists on 16 Songs
Oct 26, 2009 4:24:22 PM: INFO: Task 10:Retrieving Acoustic Ids for 16 Songs
Oct 26, 2009 4:24:22 PM: INFO: Task 11:Started Correct Tags from MusicBrainz on 16 Songs
Oct 26, 2009 4:24:22 PM: INFO: Task 12:Started Updating tag data for 16 Songs
Oct 26, 2009 4:24:22 PM: INFO: Task 13:Started Correct Lyrics on 16 Songs
Oct 26, 2009 4:24:23 PM: WARNING: Unable to retrieve an acoustic id for song 6
Oct 26, 2009 4:24:23 PM: WARNING: Unable to retrieve an acoustic id for song 0
Oct 26, 2009 4:24:23 PM: WARNING: Unable to retrieve an acoustic id for song 4
Oct 26, 2009 4:24:23 PM: WARNING: Unable to retrieve an acoustic id for song 5
Oct 26, 2009 4:24:23 PM: WARNING: Unable to retrieve an acoustic id for song 13
Oct 26, 2009 4:24:23 PM: WARNING: Unable to retrieve an acoustic id for song 1
Oct 26, 2009 4:24:23 PM: WARNING: Unable to retrieve an acoustic id for song 8
Oct 26, 2009 4:24:23 PM: WARNING: Unable to retrieve an acoustic id for song 14
Oct 26, 2009 4:24:24 PM: WARNING: Unable to retrieve an acoustic id for song 10
Oct 26, 2009 4:24:25 PM: WARNING: Unable to retrieve an acoustic id for song 11
Oct 26, 2009 4:24:26 PM: WARNING: Unable to retrieve an acoustic id for song 2
Oct 26, 2009 4:24:27 PM: WARNING: Unable to retrieve an acoustic id for song 3
Oct 26, 2009 4:24:28 PM: WARNING: Unable to retrieve an acoustic id for song 12
Oct 26, 2009 4:24:29 PM: WARNING: Unable to retrieve an acoustic id for song 15
Oct 26, 2009 4:24:30 PM: WARNING: Unable to retrieve an acoustic id for song 9
Oct 26, 2009 4:24:31 PM: WARNING: Unable to retrieve an acoustic id for song 7
Oct 26, 2009 4:24:41 PM: INFO: Task 10:Retrieve Acoustic Ids was unable to find a match for 16 Songs
Oct 26, 2009 4:24:41 PM: INFO: Task 10:Completed retrieval of Acoustic Ids for 16 Songs
Oct 26, 2009 4:24:41 PM: INFO: Task 11:Correct Tags From MusicBrainz was unable to find a match for 12 Songs
Oct 26, 2009 4:24:41 PM: INFO: Task 11:Corrected 4 Songs from MusicBrainz successfully
Oct 26, 2009 4:24:41 PM: INFO: Task 11:Completed Correcting Tags from MusicBrainz on 16 Songs
Oct 26, 2009 4:24:41 PM: INFO: Task 12:Updated 4 tags from existing Discogs Id successfully
Oct 26, 2009 4:24:41 PM: INFO: Task 12:Update Tags from Existing Discogs Ids was unable to find a match for 12 Songs
Oct 26, 2009 4:24:41 PM: INFO: Task 12:Completed Updating Tags from Discogs for 16 files
Oct 26, 2009 4:24:41 PM: INFO: Task 13:Corrected 8 Lyrics
Oct 26, 2009 4:24:41 PM: INFO: Task 13:Unable to find a match for 8 Songs
Oct 26, 2009 4:24:41 PM: INFO: Task 13:Completed Correct Lyrics on 16 Songs
Oct 26, 2009 4:24:41 PM: INFO: Task 14:Started Clustering Albums for 16 Songs
Oct 26, 2009 4:24:41 PM: INFO: Task 14:Before clustering there were 1 albums spread over 1 MusicBrainz Release Ids
Oct 26, 2009 4:24:41 PM: INFO: 8 Songs were modified with the Autocorrector
Oct 26, 2009 4:24:41 PM: INFO: Completed Autocorrecter on 16 Songs
Here’s the same Eminem 8Mile directory of files loaded into Picard:
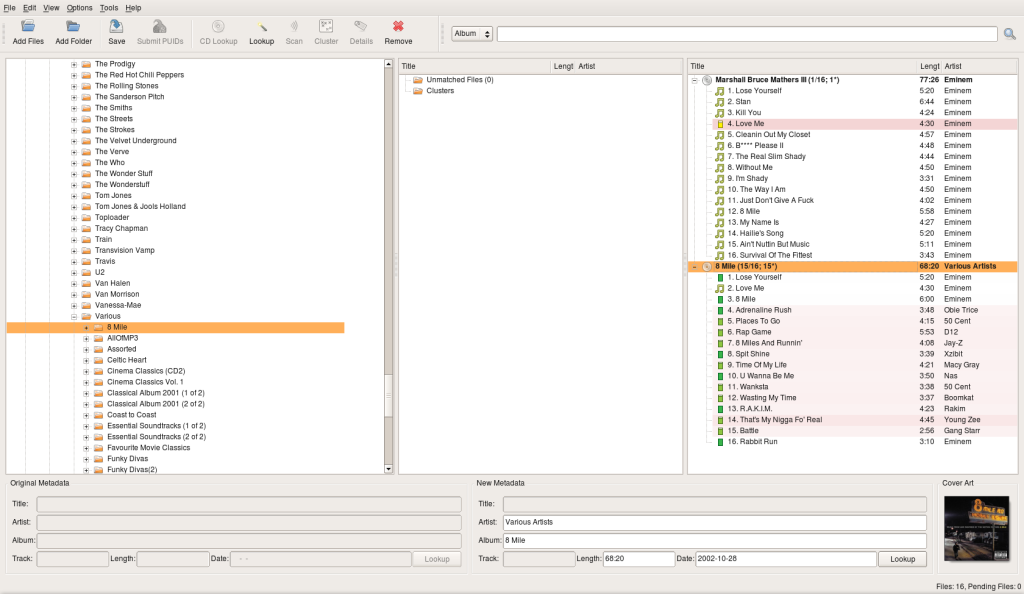
On the plus side, at least Picard manages to assign 15 out of the 16 tracks to the correct album which beats Jaikoz’s 4/16. On the minus side, Picard still leaves manual work to the user by mis-assigning track 2 “Love Me” to the wrong Album. It looks like Picard is able to generate fingerprints for all tracks though, unlike Jaikoz which fails to generate any fingerprints.