I was pretty silent last 6 weeks, as I basically was re-downloading all my music library from my cloud storage (remember I fucked up everything using the duplicate finder tool? ^^).
As a matter of fact, I think I’ll start a new fix files job as soon I’ll have re-downloaded everything, and my SK database still existing, I guess it will be way faster this time.
But still, I have some questions on how I could speed all my future fixes and renames:
do you know if there could be a way to move files to a temporary cache on a NVME, in the background, right before songkong would start fixing the files? would this make sens I/O wise ?
What is the current status of multi-threading? are all CPU threads used again during the fix task ?
Just currious
Nice to post here again by the way ! and congrats for the new release, I am really looking forward to test it !
When you upgrade to a new release of SongKong the database is recreated, but it should still be faster than before because of the fixes and improvements we have made.
No, I don’t think so, remember that SongKong is a Java program available on a number of different operating systems. therefore we stay away from OS specific optimizations, if they are not done automatically by the Java engine then we will not be doing them. Anyway it would not make much difference because as long as the files are local (not networked) then reading/writing from files will be quicker than looking up MusicBrainz releases and matching them.
Yes, that was fixed in earlier release and has not changed.
music enters the dump in monthly folder/daily folder/ -> therefore, after the first initial match and duplicates job task ends, it would be nice to allow SK to monitor this folder, and run each night to identify the newly arrived music in there (cron task?) -> doable ?
Music_matched = the folder where albums that are matched on MB are stored -> for organizational reasons I want SK to :
NOT create one single artist folder containing all the artists (showed it would grow to much, making plex uncomfortable adding new content when new scans happens) -> how to do this?
FOR THE FIRST RUN OF THE FIX TASK : SK will create one prefix folder (A, B, C, D, …) and put the respective artists in their respective prefix folder -> how to do this?
REGARDING CLASSICAL RELEASES -> all classical “artists” folder should go under a general “Classical” folder -> how to do this?
REGARDING VARIOUS ARTISTS AND COMPILATION releases -> all these releases should go under a general “Various Artists” or “Compilation” folder -> how to do this?
This folder is NOT added to plex as we want to avoid dupes!!! therefore a duplicates job need to be run first.
Music_unmatched = the folder where albums that were not matched on MB are moved from Music_new
I wonder if I better keep these albums names as they are initially, or if I use embedded tags to already name them “sort of” ?
All the albums that are not matched by SK goes here, they are simply moved from the music_new folder to here
This folder should be reprocessed from time to time
This folder is added to plex as “Music (unmatched)”
Music_processed = the folder that contains the matched and duplicates free albums / va / compilations
This is the folder where duplicates task moves the previously matched albums once it has a “winner”, only best available copy (best quality / most tracks) remains here.
One copy per album version = we keep the best version quality wise of each album version (Eg: Initial release, release with bonus tracks…)
This folder is added to plex, as music in there is dupe free and contains the best quality versions of each album/comp/va
Music_to_delete = the folder where we move the albums identified as “loosers” by the duplicate task
This folder is here as a security net, but will be emptied after checking the duplicates job was correctly run (no silly deletion of random tracks…souvenir…)
Extras :
I need to figure out a way to inform plex about the content that gets pushed to Music_processed and Music_unmatched on the fly. This to avoid plex to -re-scan the entire library again and again
Hi, sorry there is so much in this post Im struggling to take it all in, so can I suggest we break it down a bit.
Now, before worrying about your daily updates you need to reprocess your existing library so lets deal with this first. Now in this new version filenaming is no longer part of Fix Songs (you can still move songs with Watch Songs) so I would suggest basic approach would be
Fix Songs
Delete Duplicates
Rename Files
By running Delete Duplicates before Rename Files we can deal with duplicated files in their original folders and we reduce the chances of Rename Files clashing on filenames due to duplicate songs since most duplicates should now be removed.
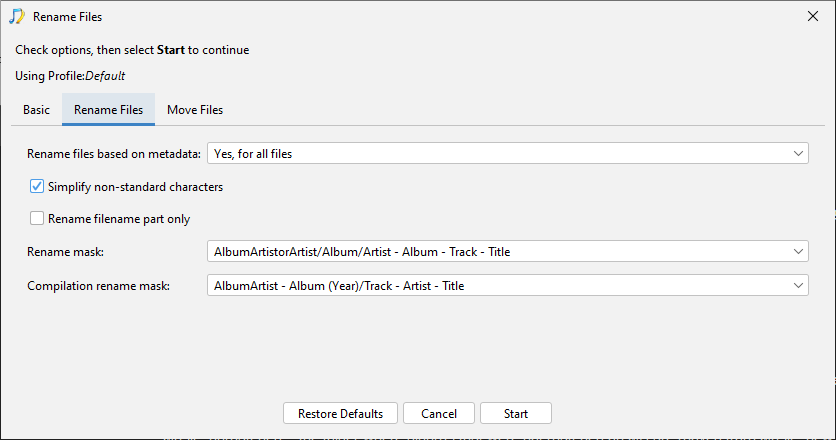
We have existing rename masks that have a top level A/B/C/D folder
e.g FirstLetterOfArtist/AlbumArtistorArtist/Album/AlbumArtistorArtist - Album - Track - Title
and put Classical in different location
e.g IsClassical/HD/AlbumArtistorArtist/Album/DiscIfMultiDisc/Artist - Album - Track - Title
and you can use separate mask for compilations to non compilations
First quesiton would be, as I now totally got rid of Roon since multiroom is a thing with plexamp -> should I not prefer to use the pelx music scanner format ? It looks like this is best practice to get plex read and organize well, right ?
Now, what do I exactly have to do in order to put classical and compilations / VA releases in a separate folder ? This is a little unclear.
Also since the GUI was changed, the job/task names are not displayed in the UI, making it mandatory to make a mouse hover to understand what section you are heading to.
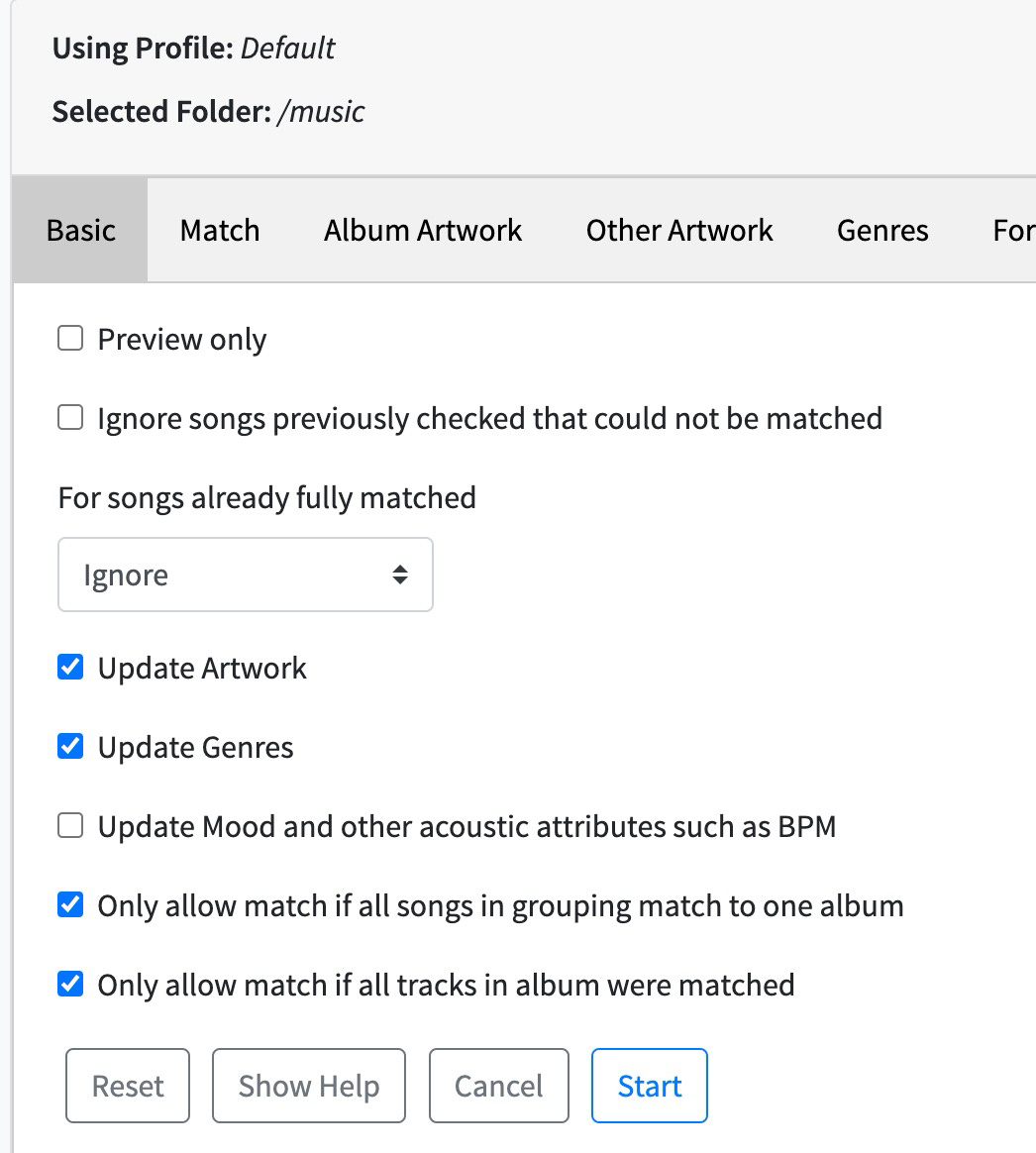
First screen of fix songs now asks me the profile I want to use, I guess I better take default in there ? (I rather do a full fix of metadata AND images, so is default the right choice?)
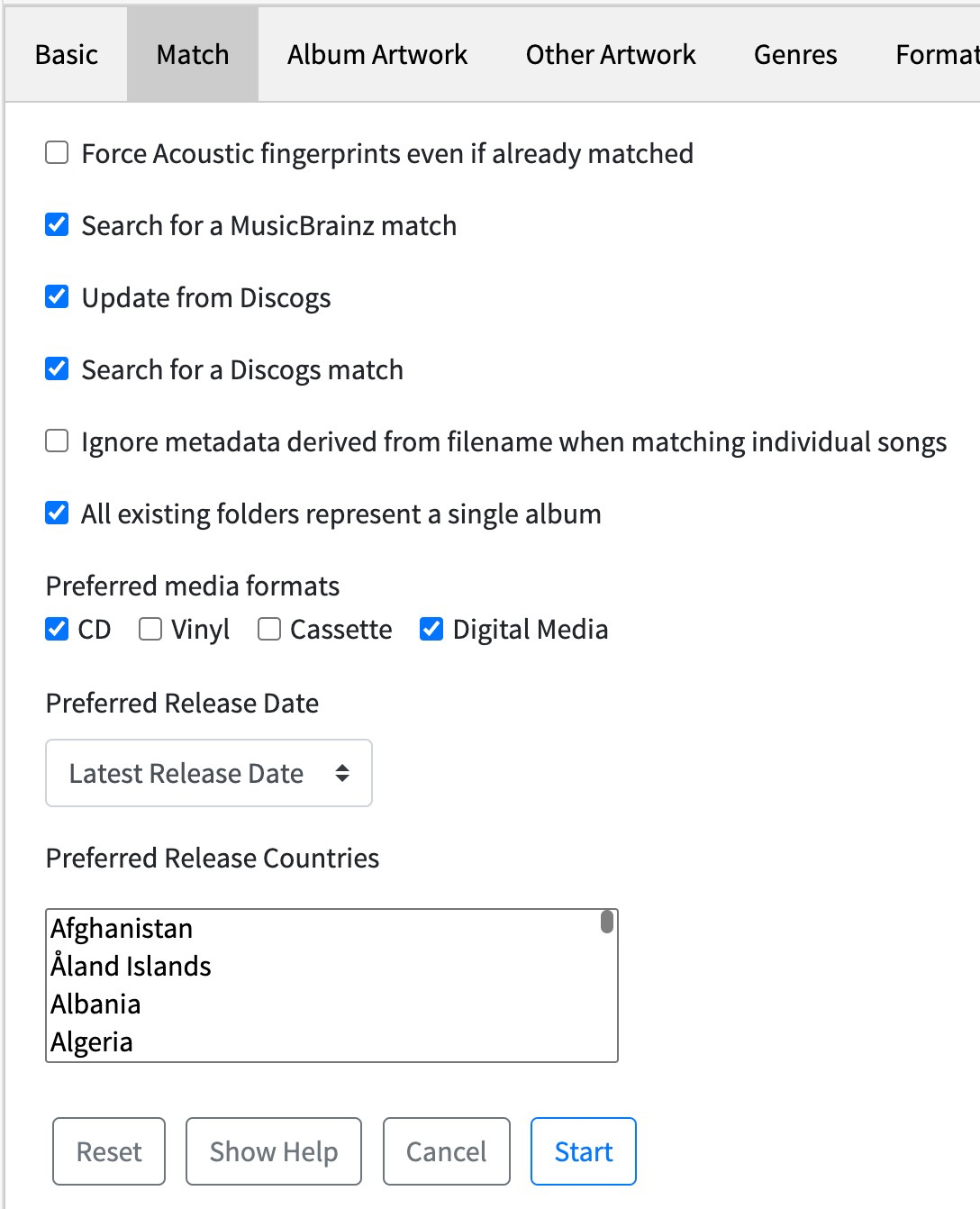
anyway can you confirm the following settings please ?
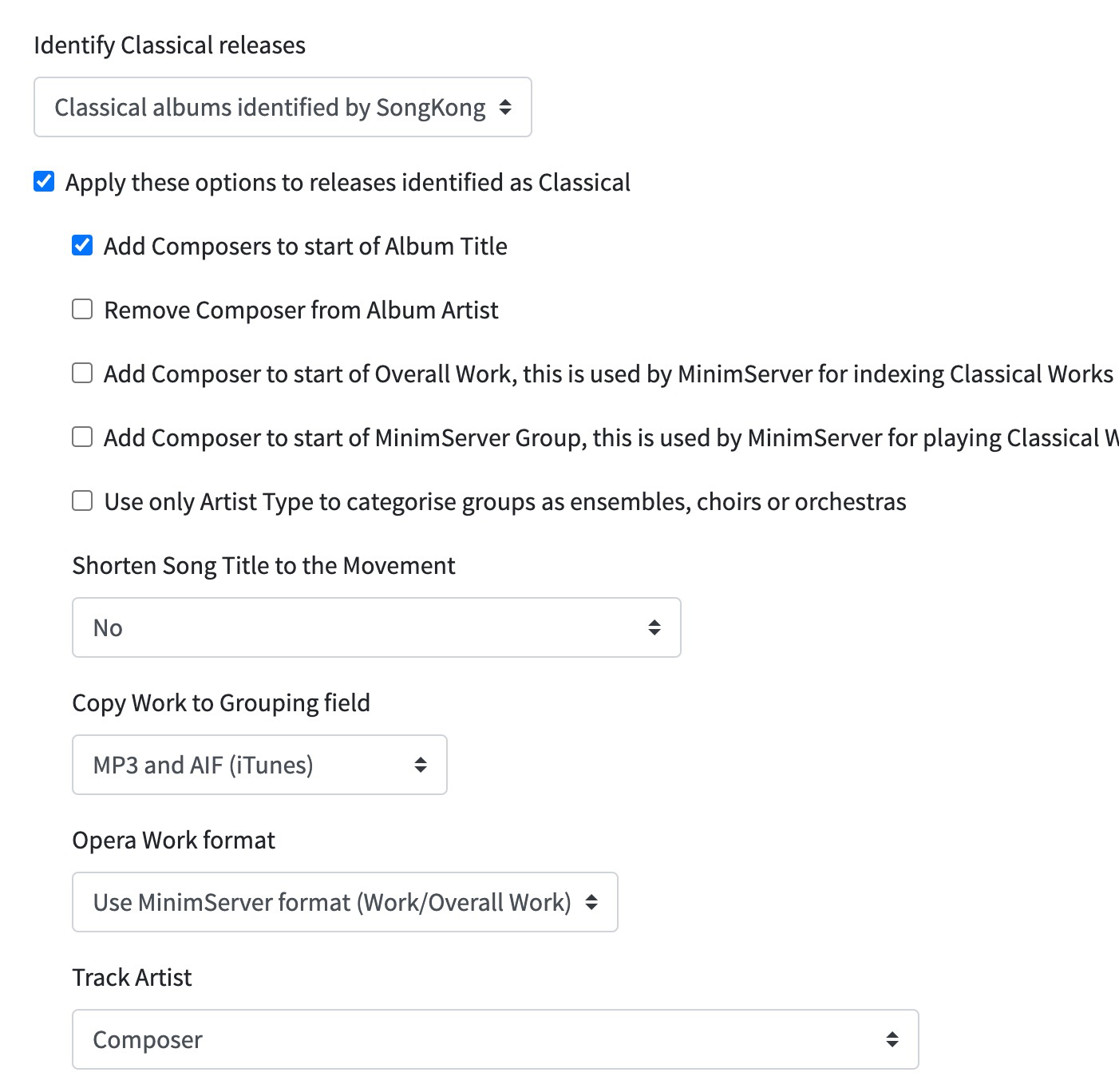
as you can see I try to avoid multiple artists folders as much as possible by selecting single artists and avoid featured artists. Also I want to only display Composer as artists for classical releases (so if the london symphony plays Berlioz, I want this album to be put in Berlioz folder, and not Berlioz, the london symphony…).
does these settings seem fine for you ? for the fix job task ?
If you want a top level folder for non classical as well you could use addClassical() this adds a PopRock folder for everything else, if this isnt quite what you want modify the addClassical Javascript function, it is currently
You can create similar function for Is Compilation.
I dont understand what you mean, please explain further.
Looks okay except:
I wouldn’t set Multi Disc Releases to Add Disc No to the release title if disc has title because this means each disc has different name, so plex may think different albums, also it means the foldername will differ at album level but it should be same, and the plex mask handles multi discs with a DiscNo subfolder. Just set it to Never add disc no to release title
You have slight problem with Classical Album artist because you can only set the Track Artist to composer, and you want to set Album Artist to composer, I think we discussed this before. Now its important to remember that Album Artist needs to be same for all songs in album, otherwise music players will split album into multiple albums and file renaming using the Album Artist field will split into multiple folders, and you will certainly have some classical albums that have different composers for different tracks.
Now if you are happy for the album artist to contain the main performers (Conductor/Orchestra) but you just want the Album Artist folder to contain composer(s) then I have one idea. The album title field usually contains a list of the Composers , then a ‘:’ then the album name. And even if originally missing then SongKongs tries to achieve this with the Add Composers to start of Album Title option, so in your rename mask you could add new function
not really, modernising the UI is one thing, but even with a flat design, a description of the tasks would be welcome. Think about new users, or people who did not use snkong in a long time. It is now neede to hover to remember / understand which icon leads you here or there. Just my UI/UX two cents
Okay, but to clarify you are not saying it used to have descriptions, just that because icons have changed would be useful to have descriptions displayed the whole time to make it easier for existing users to migrate to new version?
I don’t think there is space for permanent descriptions, in fact on my mac laptop in desktop mode (which does show descriptions to match mac guidelines) there will not be enough room if I add any more tasks.
More generally, is there somewhere I can seek for information about the logs ? What are the events I should look for ? I’d like to understand better what is happening this time.
The logs are really for my benefit in case customers have issue. It is not really expected customers will look at the logs so currently no documentation on them.
20/06/2023 02.08.10:CEST:AbstractAcoustidQuery:performBasicSubmissionQuery:SEVERE: Posting to url:http://api.acoustid.org/v2/user/lookup?format=xml&client=8XaBELgH&user=lj5NgggIwD
20/06/2023 02.08.10:CEST:AbstractAcoustidQuery:analyseErrors:WARNING: AcoustidError<?xml version='1.0' encoding='UTF-8'?>
<response><error><code>6</code><message>invalid user API key ("User with the API key does not exist")</message></error><status>error</status></response>
20/06/2023 02.08.10:CEST:AbstractAcoustidQuery:doPerformQuery:SEVERE: Acoustid Exception looking up from AcoustId:<?xml version='1.0' encoding='UTF-8'?>
<response><error><code>6</code><message>invalid user API key ("User with the API key does not exist")</message></error><status>error</status></response>
com.jthink.acoustid.exception.AcoustidException: <?xml version='1.0' encoding='UTF-8'?>
<response><error><code>6</code><message>invalid user API key ("User with the API key does not exist")</message></error><status>error</status></response>
at com.jthink.acoustid.query.AbstractAcoustidQuery.doPerformQuery(AbstractAcoustidQuery.java:299)
at com.jthink.acoustid.query.AbstractAcoustidQuery.performQuery(AbstractAcoustidQuery.java:227)
at com.jthink.acoustid.query.AcoustIdQuery.lookupUser(AcoustIdQuery.java:157)
at com.jthink.songkong.analyse.acoustid.AcoustId.isValidAcoustidUser(AcoustId.java:720)
at com.jthink.songkong.cmdline.SongKong.setUserAgent(SongKong.java:688)
at com.jthink.songkong.cmdline.SongKong.cmdlineOrRemoteModeStart(SongKong.java:1069)
at com.jthink.songkong.cmdline.SongKong.finish(SongKong.java:1284)
at com.jthink.songkong.cmdline.SongKong.main(SongKong.java:1314)
20/06/2023 02.08.10:CEST:AcoustId:isValidAcoustidUser:SEVERE: Problem connecting to AcoustId, assume current User okay
20/06/2023 02.08.10:CEST:SongKong:setUserAgent:WARNING: end
Just to be sure, if I check “SaveComplete” events in the logs, these are the files that are done being fixed, right ? So I an consider all files that are NOT “SaveComplete” are the ones which are not matched with MB or Discogs ?
In fact on first run all files should be saved because SongKong adds a SONGKONG_ID to every song so that later runs know if we have ever tried to match the song before (used by Ignore songs previously checked that could not be matched option)
Also, worth noting that songs can be matched to Acoustid Albums , and AcoustId Song Only as well.
You cannot rely on the logs for any kind of automated processing.





 thanks !
thanks !